
The StreamReader and Writer classes can take either a character encoding parameter or be left to use the platform default encoding
Previous |
Next |
Write code that uses objects of the classes InputStreamReader and OutputStreamWriter to translate between Unicode and either platform default or ISO 8859-1 character encodings.
I was surprised that this objective was not be emphasised in the JDK1.2 exams as internationalization has been enhanced and is a big feature with Java. It's nice to sell software to a billion Europeans and Americans but a billion Chinese would be a nice additional market (even if you only got 10% of it). This is the kind of objective that even experienced Java programmers may not have experience with, so take note!.
Java uses two closely related encoding systems UTF and Unicode. Java was designed from the ground up to deal with multibyte character sets and can deal with the vast numbers of characters that can be stored using the Unicode character set. Unicode characters are stored in two bytes which allows for up to 65K worth of characters. This means it can deal with Japanese Chinese, and just about any other character set known. You will be pleased to know that you don't have to give examples of any of these for the exam.
Although Unicode can represent almost any character you would ever likely to use it is not an efficient coding method for programming. Most of the text data within a program uses standard ASCII, most of which can easily be stored within one byte. For reasons of compactness Java uses a system called UTF-8 for string literals, identifiers and other text within programs. This can result in a considerable saving by comparison with using Unicode where every character requires 2 bytes.
The StreamReader class converts a byte input (i.e. not relating to any character set) into a character input stream, one that has a concept of a character set. If you are only concerned with ASCII style character sets you will probably only use these Reader classes in the form with the constructor
InputStreamReader(InputStream in)
This version uses the platform-dependent default encoding. In
JDK 1.1 this default is identified by the file.encoding system
property. There seems to be no standard way of finding out what
encodings are supported on your platform The default encoding is
generally ISO Latin-1 except on a Mac where it is MacRoman.. If
this system property is not defined, the default encoding
identifier is 8859_1 (ISO-LATIN-1). The assumption seems to be that
if all else fails, revert back to English. Experimenting with other
character sets is problematic as the characters may not show up
correctly if you environment is not configured appropriately. Thus
if you attempt to output a character from the Chinese character set
you system may not support it.
If you are dealing with other character sets you can use
InputStreamReader(InputStream in, String encoding);
|
|
The StreamReader and Writer classes can take either a character encoding parameter or be left to use the platform default encoding |
Remember that the InputStream comes first and encoding second.
The InputStreamReader class has a read() method and the OutputStreamWriter has a write() method that read and write characters. When the read method is called it reads bytes from the input stream and converts them to Unicode characters using the encoding specified in the stream constructor. When the write() method is called the the characters from the stream are converted to their corresponding byte encoding and stored in an internal buffer. When the buffer becomes full the contents are written to the underlying byte output stream.
The sample code for GreekWriter writes a text output file containing some letters in the Greek alphabet. If you open this file Out.txt with an editor you will just see what looks like junk.
import java.io.*;
class GreekWriter {
public static void main(String[] args) {
String str = "\u03B1\u03C1\u03B5\u03C4\u03B7";
try {
Writer out =
new OutputStreamWriter(new FileOutputStream("out.txt"), "8859_7");
//8859_7 is the ISO code for ASCII plus greek, although this
//example also works on my machine if it is set to UTF8
out.write(str);
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
import java.io.*;
import java.awt.*;
class GreekReader extends Frame{
/*******************************************************
*Companion program to GreekWriter to illustrate
*InputStreamReader and OutputStreamWriter as part
*of the objectives for the Sun Certified Java Programmers
*exam. Marcus Green 2000
*********************************************************/
String str;
public static void main(String[] args) {
GreekReader gr = new GreekReader();
gr.go();
gr.setWin();
}
public void go(){
try {
FileInputStream fis = new FileInputStream("out.txt");
InputStreamReader isr = new InputStreamReader(fis,"8859_7");
Reader in = new BufferedReader(isr);
StringBuffer buf = new StringBuffer();
int ch;
while ((ch = in.read()) > -1) {
buf.append((char)ch);
}
in.close();
str = buf.toString();
} catch (IOException e) {
e.printStackTrace();
}
}
public void paint(Graphics g) {
//paint method automatically called by the system
Insets insets = getInsets();
int x = insets.left, y = insets.top;
//Add 30 to y or we will only see the
//downstrokes of the letters
g.drawString(str, x, y +30);
}
public void setWin(){
//Nice big font so we can see the characters.
Font font = new Font("Monospaced", Font.BOLD, 59);
setFont(font);
setSize(200,200);
setVisible(true);
//Show the frame
show();
}
}
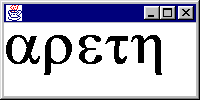

Which of the following statements are true?
1) The OutputStreamWriter must take a character encoding as a
constructor parameter
2) The default encoding for the OutputStreamWriter is ASCII
3) The InputStreamReader and OutputStreamWriter may take a
character encoding as a constructor
4) InputStreamReader must take a stream as one of its
constructors
Which of the following statements are true?
1) Java can display character sets independently of the
underlying operating system
2) The InputStreamReader class may take an instance of another
InputStream class as a constructor
3) An InputStreamReader may act as a constructor to an
OutputStreamReader to convert between character sets
4) Java uses the ASCII encoding system to store strings
internally
Which of the following are correct signatures for InputStreamReader?
1) InputStreamReader(InputStream in, String encoding);
2) InputStreamReader(String encoding,InputStream in);
3) InputStreamReader(String encoding,File f);
4) InputStreamReader(InputStream in);
Which of the following are methods of the InputStreamReader class?
1) read()
2) write()
3) getBuffer()
4) getString()
Which of the following statements are true?
1) Java uses unicode to internally to store string literals
2) Java uses ASCII to internally store string literals
3) Java uses UTF-8 to internally store string literals
4) Java uses the platform native encoding to store string
literals
3) The InputStreamReader and OutputStreamWriter may take a
character encoding as a constructor
4) InputStreamReader must take a stream as one of its
constructors
For option 1 you might have thought that "character encoding" refers to a char type. It might be more specific to call it a "character encoding string" but Sun sometimes uses the short form of "character encoding".
1) Java can display character sets independently of the
underlying operating system
2) The InputStreamReader class takes may take an instance of
another InputStream class as a constructor
Although Java can store characters independently of the underlying operating system, the appropriate font must be installed on the underlying operating system in order to display those characters. Generally streams are chained with like streams, ie InputStreams take constructors of other InputStreams and OutputStreams take constructors of OutputStreams. Java uses the UTF encoding system to store strings internally.
1) InputStreamReader(InputStream in, String encoding);
4) InputStreamReader(InputStream in);
If you do not specify an encoding the JVM will assume the platform default encoding
1) read()
3) Java uses UTF-8 to internally store string literals
The Sun API docs on InputStreamReader and
OutputStreamWriter
http://java.sun.com/products/jdk/1.2/docs/api/java/io/OutputStreamWriter.html
http://java.sun.com/products/jdk/1.2/docs/api/java/io/InputStreamReader.html
JavaCaps on this topic
http://www.javacaps.com/scjp_io.html#objective2
Everything you could want to know about unicode
http://www.unicode.org/
An explanation of how UTF encoding works
http://prominence.com/books/net/cd/html/utf.html
Previous |
Next |